傳統在雲端平台上,通常都會有現成的Load Balance服務,提供彈性負載分流到自己的應用程式集群
假如我們希望在私有雲下,或是在自己家裡,希望也可以建置Load Balancer的話,透過硬體的F5機制成本高昂
這個時候,就可以依賴Nginx的套件了
其特點是可以大量處理併發連線
Nginx在官方測試的結果中,能夠支援五萬個並列連接,而在實際的運作中,可以支援二萬至四萬個並列連結。
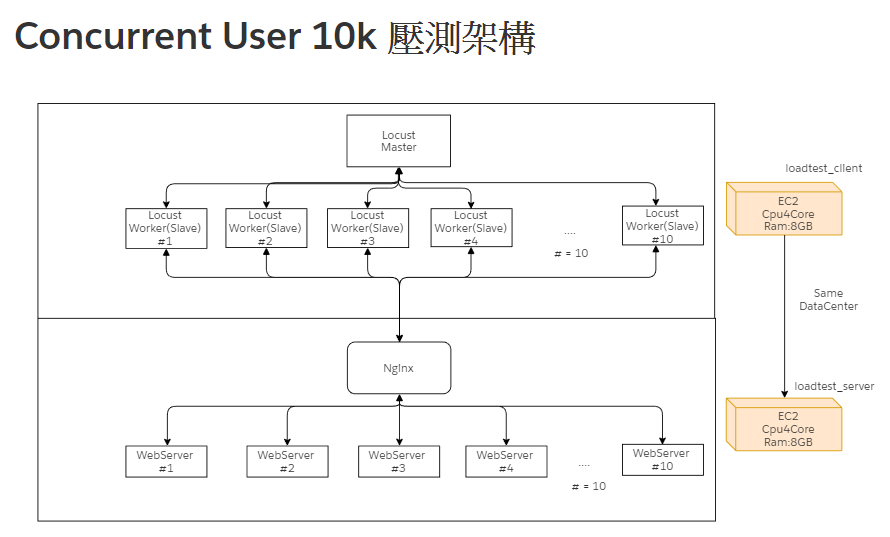
假設以下情境,我們希望建立一個WebTest的測試環境,統一1個domain的port為進入點,但背後可能有很多台Api或子web站台來支持不同的服務與運算

因此這個時候,我們需要nginx來做為API.Domain的代理服務器,將實際的請求轉導到對應的內部伺服器,再把結果回傳回去
我們以Docker為測試環境,方便模擬多台伺服器的情況,而Docker在容器間的網路連線上,提供許多Api可以方便我們建置集群
我透過Python寫一隻輕量運算的api server(這也可以是其他案例,例如取得天氣、股市、時間…等)作為範例
當api層級深度太高的話,瓶頸識別會愈來愈不單純,因此我先在這邊假定問題點就是單一台吞吐量有上限,因此我們透過多台+load balance來支持同時併發的連線請求
小型的python get uuid tornado web server
import datetime
import socket
import json
import os
import sys
import uuid
from collections import OrderedDict
from multiprocessing.pool import Pool
import asyncio
import tornado
from tornado import web, gen
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from mongodb_helper import MongoDBHelper
sys.path.append( os.path.abspath( os.path.join( os.path.abspath( __file__ ), os.pardir, os.pardir ) ) )
sys.path.append( "/usr/src/app" )
def get_server_ip():
return (([ip for ip in socket.gethostbyname_ex( socket.gethostname() )[2] if not ip.startswith( "127." )] or [[(s.connect( ("8.8.8.8", 53) ), s.getsockname()[0], s.close()) for s in [socket.socket( socket.AF_INET, socket.SOCK_DGRAM )]][0][1]]) + ["no IP found"])[0]
def log(from_ip, action, data):
service = MongoDBHelper( host="mongodb-dev", port=27017 )
service.change_db( "tornado_web_test" )
service.insert_data( collection_name="requestLog_"+get_server_ip() , data=dict( from_ip=from_ip, action=action, data=data ) )
class WebTestEntryHandler( tornado.web.RequestHandler ):
def initialize(self, pool=None):
self.local_pool = pool
def set_default_headers(self):
self.set_header( "Access-Control-Allow-Origin", "*" )
self.set_header( "Access-Control-Allow-Headers", "x-requested-with" )
self.set_header( 'Access-Control-Allow-Methods', 'POST, GET, OPTIONS' )
self.set_header( "Access-Control-Allow-Headers", "Content-Type" )
self.set_header( 'Content-Type', 'application/json' )
def options(self, *args, **kwargs):
# no body
self.set_status( 200 )
self.finish()
def get_uuid(self):
requestTime = datetime.datetime.today().strftime( '%Y-%m-%d %H:%M:%S.%f' )[:-3]
result = str(uuid.uuid4())
responseTime = datetime.datetime.today().strftime( '%Y-%m-%d %H:%M:%S.%f' )[:-3]
resultObj = OrderedDict([("IsSuccess", True), ("Data", result), ("RequestTime",requestTime), ("ResponseTime", responseTime)])
return resultObj
def common(self, action):
try:
if action == "get_uuid":
resultObj = self.get_uuid()
else:
resultObj=dict(IsSuccess=False, Message="action not found")
self.local_pool.apply_async(log, (self.request.remote_ip, action, resultObj,) )
except Exception as err:
resultObj = dict( IsSuccess=False, Message=str(err) )
if resultObj != None:
self.write( json.dumps( resultObj ) )
@gen.coroutine
def get(self):
action = None
if self.get_argument('action', default=None) != None:
action = self.get_argument('action')
self.common(action=action)
@gen.coroutine
def post(self):
action = None
if self.get_argument( 'action', default=None ) != None:
action = self.get_argument( 'action' )
self.common( action=action )
def serve(host, port, pool):
import socket
if host in ["", None]:
ip_address = socket.gethostbyname( socket.gethostname() )
else:
ip_address = host
# tornado.options.parse_command_line() not work for websocket
app = tornado.web.Application( default_host=ip_address, handlers=[
(r"/webtest", WebTestEntryHandler, dict( pool=pool )),
] )
http_server = HTTPServer( app, max_body_size=1500 * 1024 * 1024 * 1024 )
http_server.listen( port ) # 1.5M
io_loop = tornado.ioloop.IOLoop.current()
print("rest server ready to start!")
io_loop.start()
def app(pool):
rest_host_str = "0.0.0.0"
rest_port_str = "6969"
rest_port = int( rest_port_str )
# define( "port", default=rest_port, help="run on the given port", type=int )
serve( rest_host_str, rest_port, pool )
if __name__ == "__main__":
pool = Pool( processes=4 ) # start 4 worker processes
app(pool)
註:上面python的實作,為了統計server的請求處理數據,因此加入了寫入mongodb的異步流程,可以參考使用,呼叫mongodb連線時,記得也要使用container name哦,不然會連不到
將其server打包成容器
FROM python:3
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD [ "python", "./rest_server.py" ]
#建立測試api 服務容器映像檔
sudo docker build -t tornado-web-test .
#建立容器群網路,網路內的容器可直接互連
sudo docker network create webtest
#建立容器實例(共3台),分別佔用10001, 10002, 10003
sudo docker run -d –name webtest001 –network=”webtest” -p 10001:6969 tornado-web-test
sudo docker run -d –name webtest002 –network=”webtest” -p 10002:6969 tornado-web-test
sudo docker run -d –name webtest003 –network=”webtest” -p 10003:6969 tornado-web-test
分別請求10001,10002,10003的http://xxx.xxx.xxx.xxx:10001/webtest?action=get_uuid後,可以正常的回應即可

接著主要工作就是配置nginx,其設定檔,很明確的說明了我希望它扮演的角色
nginx.conf
http{
upstream webtest.localhost {
server webtest001:6969;
server webtest002:6969;
server webtest003:6969;
}
server {
listen 10000;
#ssl_certificate /etc/nginx/certs/demo.pem;
#ssl_certificate_key /etc/nginx/certs/demo.key;
gzip_types text/plain text/css application/json application/x-javascript
text/xml application/xml application/xml+rss text/javascript;
server_name localhost;
location / {
proxy_pass http://webtest.localhost;
}
}
}
events {
worker_connections 1024; ## Default: 1024
}
注意:這邊的webtest1~3的port號都是6969,雖然在之前docker run的時候,有expose綁到其他port號,但是在docker的容器網路內部仍是採用原本容器的設定,因此這邊一定要用容器配置,而不是容器expose的配置,這邊找了一陣子
關於upstream的標籤,官方文件如下:
範例:
upstream backend {
server backend1.example.com weight=5;
server 127.0.0.1:8080 max_fails=3 fail_timeout=30s;
server unix:/tmp/backend3;
server backup1.example.com backup;
}
標籤下,我們可以定義伺服器群組,各別伺服器可以監聽不同的port,而且可以TCP/Socket混用
預設,請求會被透過round-robin balancing方法的權重來分配到不同的伺服器,以此為例,每7個請求,會被分配5個請求到backend1.example.com,還有2個分別被轉送到2、3伺服器
假如轉送過程中,有發生error,該請求會自動pass給下一個伺服器,直到所有的伺服器都試過為止。假如沒有任何伺服器可以回傳正確的結果,那用戶端的通訊結果將會是最後一台伺服器的訊息。
我們啟動Nginx容器,並試著去連線對外的10000 port
#nginx docker command
sudo docker run –name web-test-nginx –network=”webtest” -p 10000:10000 -v /home/paul/webtest/nginx/conf.d/nginx.conf:/etc/nginx/nginx.conf:ro -d nginx nginx-debug -g ‘daemon off;’
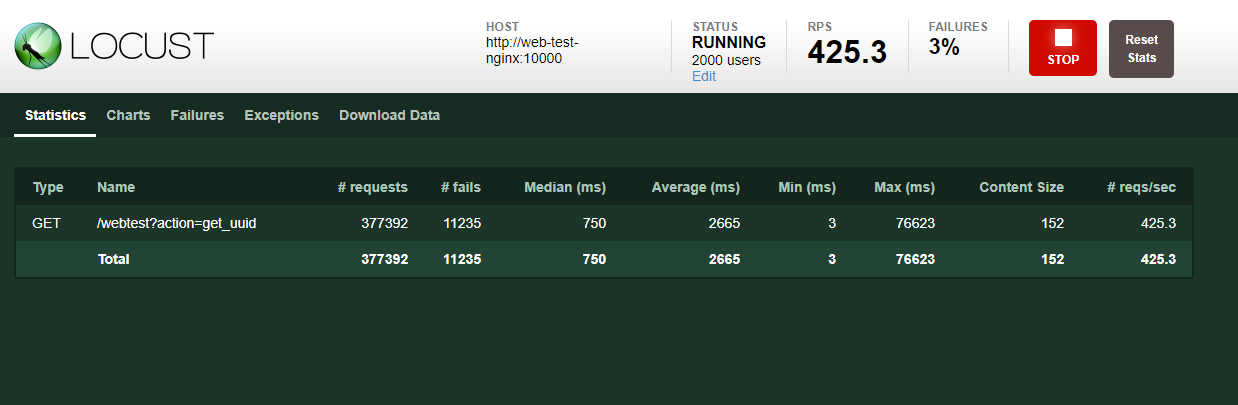
實測:http://xxx.xxx.xxx.xxx:10000/webtest?action=get_uuid

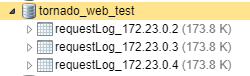
打網址,若可以出現這個畫面,那就代表可以work了,多打幾次後,我追蹤mongodb裡的log,可以看到不同的server都有接到請求

大工告成!!
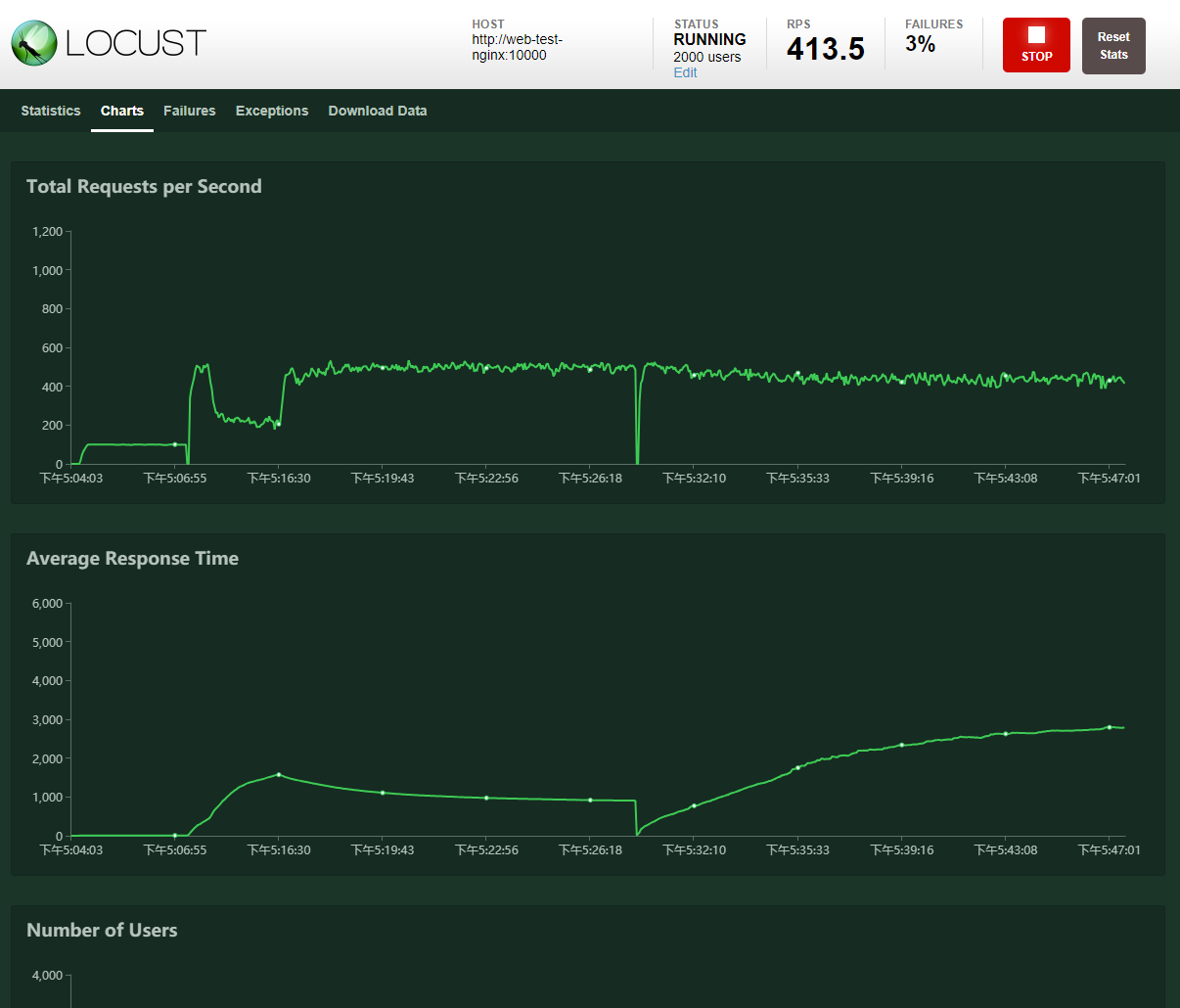
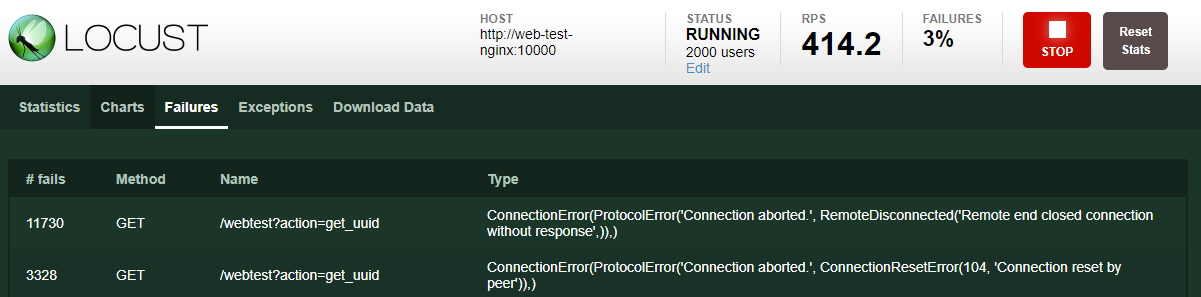
透過這樣的架構,我們可以讓原本單一一台的請求量提升到n台,假如nginx的配置沒有爆的話,那只要擔心後端的每個端點是否服務正常(這關系到監控機制)
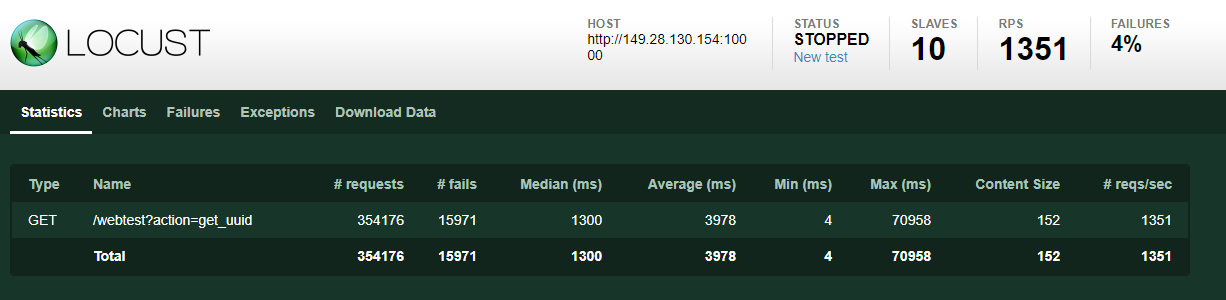
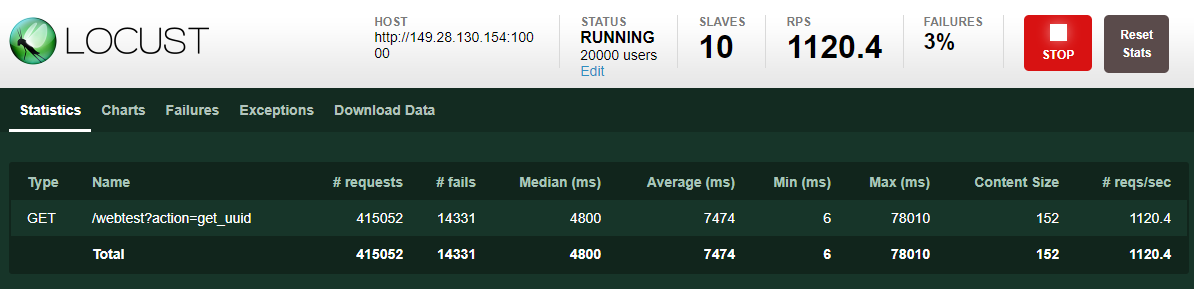
當然,docker、vm,個人電腦都有其物理極限,包含網卡、頻寬,伺服器的連線上限…etc,因此負載測試這個issue,有時因為成本過高,我們會測出單位的負載量後再加倍估算。
這個就另開討論吧…