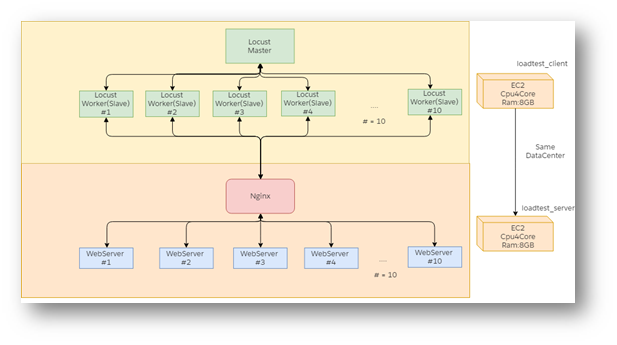
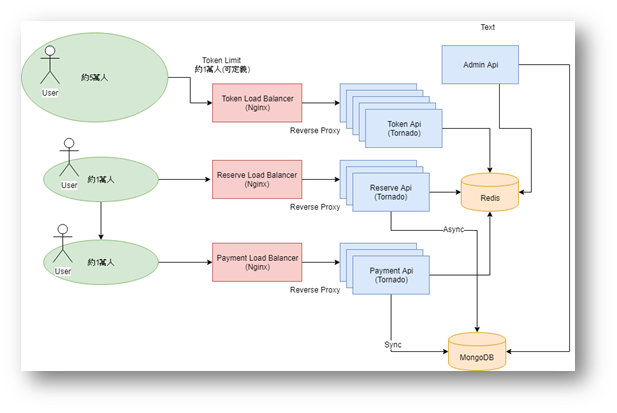
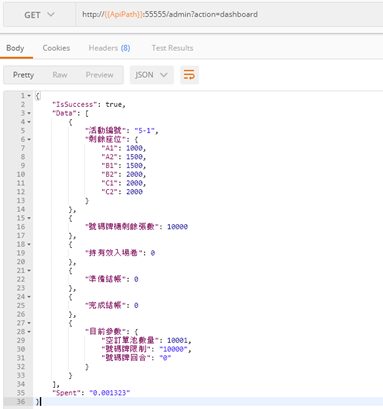
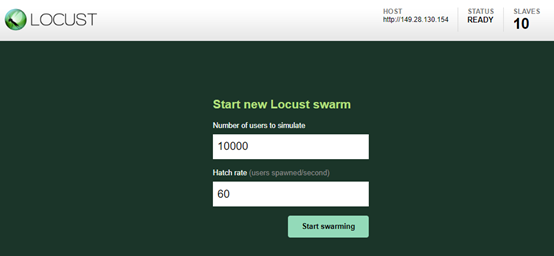
提出者:Betrand Meyer在19888年提出
OCP(The Open-Closed Principle):開放-封閉原則
如果程式的區塊一旦變動,就會產生一連串的反應,導致相關使用到的模組都必須更動,那麼這個程式碼就具備bad smell
OCP建議我們應該進行重構
如果OCP原則應用正確的話,那麼,以後再進行”同樣”的需求變動時,就只需要增加新的程式碼,而不用再調整”已經”正常運行的程式碼
其特徵為2:
1.對於擴展是開放的(open for extension)
2.對修改是封閉的(closed for modification)
如何可以「不變動模組原始碼但改變行為呢?」,OOP讓他能做到的機制就是抽象(Abstract)
建立可以固定能”描述”可能行為的抽象體作為抽象基底類別
模組針對抽象體進行操作。透過抽象體的衍生,就可以擴展此模組的行為
不遵循OCP的簡單設計的程式如下,Client直接使用了ServerImplementA的類別方法。
using System;
public class Program
{
public class Client
{
public void run()
{
var server = new ServerImplementA();
server.Start();
}
}
public class ServerImplementA
{
public ServerImplementA()
{
}
public void Start()
{
Console.Write("ServerImplement A Running");
}
}
public static void Main()
{
new Client().run();
}
}
註:這種直接透過實作達成目的,雖然沒有滿足ocp的要求,不是oop的設計原則,但是並不一定是不好的哦。
因為能解決問題的程式就是好程式,若這樣的程式需求變動可能性低或目的性明確的話,或許這種程序式的程式設計風格(Procedural programming Style)反而意圖更明確好懂呢。
此例中:Client使用了Implement A的類別,這是一種既不開放又不封閉的Client
若遵循OCP來做設計,使用策略模式(Strategy)可以重構他
using System;
public class Program
{
public class Client
{
public void run(string type)
{
ClientInterface client = null;
if (type=="A")
client = new ServerImplementA();
if (type=="B")
client = new ServerImplementB();
if (client!=null)
client.Start();
}
}
interface ClientInterface
{
void Start();
}
public class ServerImplementA:ClientInterface
{
public ServerImplementA()
{
}
public void Start()
{
Console.WriteLine("ServerImplement A Running");
}
}
public class ServerImplementB:ClientInterface
{
public ServerImplementB()
{
}
public void Start()
{
Console.WriteLine("ServerImplement B Running");
}
}
public static void Main()
{
Client client = new Client();
client.run("A");
client.run("B");
}
}
我們透過封裝Client的固定行為”Run”,拉到抽象體(策略模式的抽象載體為interface)
註:書中的案例發生了Client若使用了Server的程式時,抽象體為什麼要叫ClientInterface呢?
作者提到:抽象類別和它們的客戶的關係要比實作它們的類別關係更密切一點
那麼,當我們要擴充B的實作的時候,只需要針對B去”增加”實作,然後Client的使用端,不用再去改到使用行為,當然策略模式使用interface來解決抽象體
那麼簽章異動時(例如方法,參數),那麼仍然是會面對到策略模式帶來的副作用!
另一種樣版方法模式(Template Method)
using System;
public class Program
{
public class Client
{
public void run(string type)
{
ServerInterface client = null;
//封閉的地方
if (type=="A")
client = new ServerImplementA();
//開放的地方
if (type=="B")
client = new ServerImplementB();
}
}
public abstract class ServerInterface
{
public ServerInterface()
{
this.Start();
}
public abstract void Start();
}
//不變的地方
public class ServerImplementA:ServerInterface
{
public ServerImplementA()
{
}
public override void Start()
{
Console.WriteLine("ServerImplement A Running");
}
}
//開放的地方
public class ServerImplementB:ServerInterface
{
public ServerImplementB()
{
}
public override void Start()
{
Console.WriteLine("ServerImplement B Running");
}
}
public static void Main()
{
//不變的地方
Client client = new Client();
//開放的地方
client.run("A");
client.run("B");
}
}
透過抽象類別的實作,其實針對使用端來說,差不多差不多,都是為了抽象化,讓Client使用上足以一致性
以我抽象類別實作的好處是你可以將部分共同的實作封裝在抽象類別中!讓重覆的行為更被集中!以上面的例子,就是將Start的 行為抽到Constructor去
而抽象體使用介面或是抽象類別來達成哪個好?以結果論則是視使用上是否足夠抽象來決定
這兩個模式是滿足OCP最常用的方法
參考書摘-無瑕的程式碼-敏捷完整篇 物件導向原則、設計模式與C#實踐