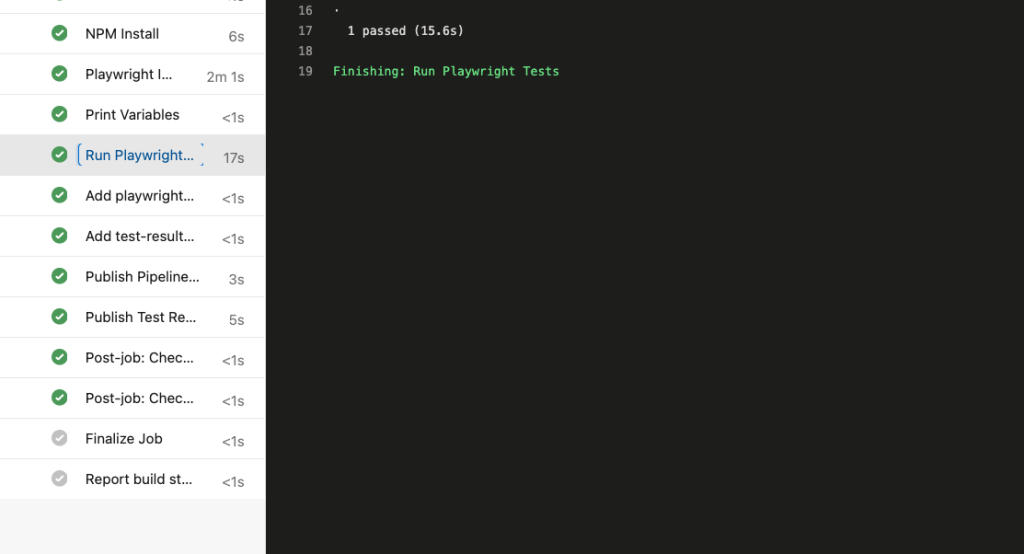
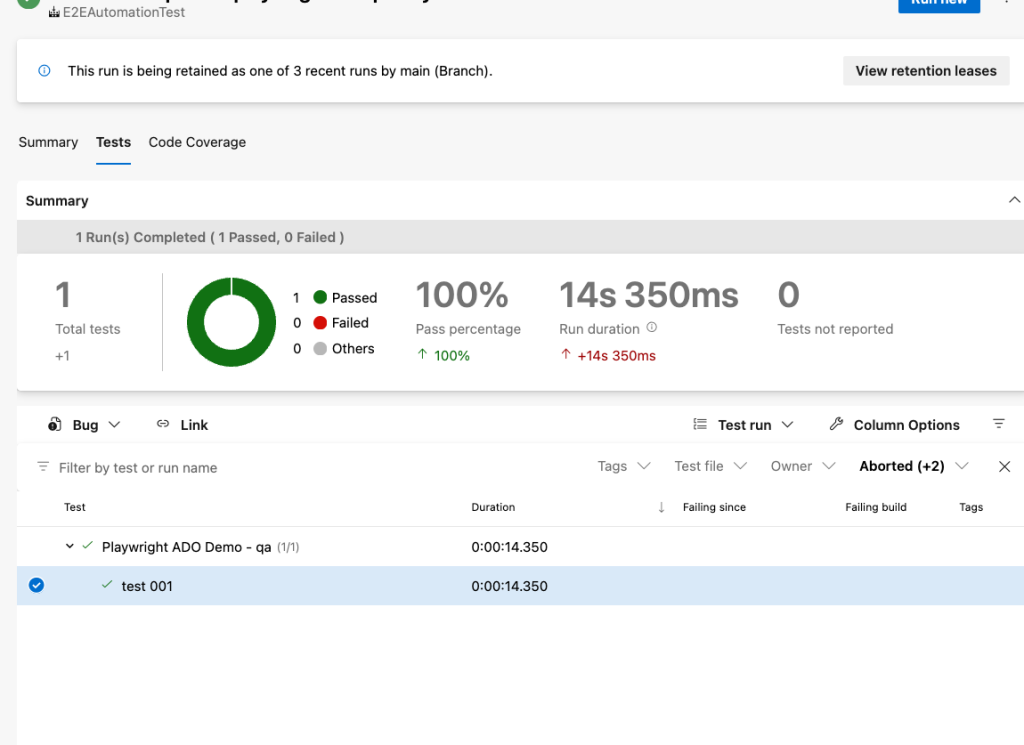
我問 ChatGPT,它回答我:
在自動化測試中需要關注以下幾個重點:
1. 測試範圍選擇(Test Scope Selection)
選擇適合自動化的測試用例,通常會選擇那些重複性高、穩定、且在多個版本中都會執行的用例,如回歸測試、API測試等。對於容易變動且難以自動化的部分,則可能更適合手動測試。
2. 測試腳本的可維護性(Maintainability of Test Scripts)
要確保自動化測試腳本易於維護,編寫腳本時應保持簡潔、模組化並遵循乾淨的代碼原則。當應用程式更新時,測試腳本需要能夠方便地做出調整。
3. 測試用例的穩定性(Stability of Test Cases)
自動化測試應該要具備穩定性,避免 flaky tests(不穩定測試),即某些測試結果偶爾會通過,偶爾會失敗的情況。可以通過確保測試環境穩定、避免依賴外部因素等方式來提高測試的穩定性。
4. 測試數據管理(Test Data Management)
自動化測試需要有效管理測試數據,確保測試數據是獨立且可控的。這意味著測試腳本不應該依賴於生產環境數據,並且應該能夠生成或重置測試數據。
5. 報告和記錄(Reporting and Logging)
測試報告應該能夠詳細展示測試結果,包括測試通過與失敗的用例、失敗的原因、錯誤日誌等,以方便快速定位問題並作出相應調整。
6. 異常處理和重試機制(Exception Handling and Retry Mechanism)
自動化測試腳本應該具有良好的異常處理機制,能夠在遇到錯誤時記錄詳細信息,並且在合適的情況下進行重試。這可以避免因網絡不穩定或暫時性問題導致的測試失敗。
7. 持續集成(Continuous Integration, CI)
自動化測試應與持續集成工具(如 Jenkins、GitLab CI 等)相結合,確保測試能夠在代碼變更時及時執行,並且能自動生成測試報告,以方便追蹤代碼品質。
8. 測試環境的隔離和一致性(Environment Isolation and Consistency)
測試環境應該與開發和生產環境相隔離,並且要保持一致性,以避免測試結果受到環境差異的影響。可以使用 Docker 或虛擬機等工具來確保環境的一致性。
9. 測試效率和執行速度(Test Efficiency and Speed)
自動化測試需要在合理的時間內完成,過長的執行時間可能會影響開發和發布節奏。因此需要平衡測試覆蓋率和測試效率,並嘗試使用並行執行或分佈式測試來加速測試流程。
10. 選擇合適的測試工具和框架(Choosing the Right Tools and Frameworks)
根據項目的需求、技術棧和團隊熟悉程度來選擇合適的自動化測試工具和框架,如 Selenium、Appium、Cypress、Robot Framework 等。不同工具有其優勢和適用場景,選擇適合的工具能提高開發效率。
關注這些重點,可以有效地構建和維護自動化測試流程,提高測試效率和產品質量。
以上是ChatGPT整理的摘要,若能在產品開發階段就關注可測試性,其實 對於後續導入測試框架會有事半功倍的效果
以下是我的觀點,幾個應該前期產品設計與開發就該涉獵的重點:
首先,最基本的是測試獨立性。雖然環境設定或第三方服務可能有些麻煩,但這些通常可以透過 Mocking 或在指定環境下關閉來解決,視測試重點而定。然而,更麻煩的是如何確保測試數據的獨立性,這直接關係到測試案例的穩定性。如果每次生成測試數據時,數據數量不一致(例如,原本只有 1 筆,重跑後變成多筆,甚至超過 10 次導致新分頁出現),那麼原本會通過的案例可能在第 10 次執行時突然失敗。
設計及維護測試數據本身是一項高成本的活動,因此在開發初期理清數據流相當重要。數據往往存在相依性,例如,有人員資訊但沒有權限資訊,某些功能就無法運作。因此,確定最小可動範圍是功能性測試的第一步,通常專案中有整合可重覆與重置的資料庫整合測試框架,我認為極有助於這一塊議題的發展(以我們是使用了.Net Core + EntityFramework + Respawn套件 (https://www.nuget.org/packages/respawn)達成數據可測試性框架,有興趣可以自行再深入了解。接著,測試的獨立性要求在同一版本或不同版本間能重複執行與持續執行。例如,若隨版本更新而需要同步更新測試數據,否則新功能可能會因不相容的數據而壞掉。因此,功能測試時也要考慮數據的相容性。雖然設計上沒有絕對的好壞,但一致性與簡單易懂是設計的原則。
接著,關於程式數據生成,在日常功能測試時,RD 可以設計資料生成機制,將測試任務和迴歸測試任務拓展至 RD 層級,要求他們在各環境中確保重複驗證功能性。這樣 RD 就會設計出透過程式生成數據的機制(大家都怕麻煩),對測試資料的建立與生成很有幫助。例如,我們近期產品開發時,我會規劃一個「示範客戶/公司」,由示範客戶下 來建立獨立的使用者,自有的權限,自有的相關數據,而不會影響其他客戶,並透過程式生成示範產品的基本可動數據,確保每次上版時能自動更新,這樣就能銜接更進階的測試,特別是涉及外部同步的資料。最好隨時備妥可重複的模擬資料,確保測試流程順暢。
註:以上示範了在 Multi-Tenant 架構下,如何在前期設計中獨立控制資料欄位。如果不是採用這種架構,也可以從資料庫層面切割客戶,這樣做其實沒有問題,主要還是跟架構成本有關。但一旦確立了標準的 schema,接下來就是如何確保系統在最小可行範圍內運作。
總結來說,一切還是圍繞在成本效益比(C/P 值)上。多數專案或產品因為看不到短期效益而猶豫不前,這種情況很常見。就像決定一家餐廳的存亡時,還在考慮菜單字體好不好看,這樣很難說服自己行動。因此,效益和成本必須一起考慮。建立自動化測試也是如此,如果產品在撰寫和執行測試案例時不夠靈活,造成困難,這就會成為一大門檻。大多數阻礙你前進的問題,不是工具怎麼用,而是當你開始動手時,不知道能不能處理後續的麻煩。