最近因為有要整合ELK方案的需求,因此又再度接觸了這個曾經相當熟悉的工具,還記得那個時候(也才1年多前),還是在2.x版左右,kibana的介面還是長這個樣子的時候。
在先前的公司,有平台團隊專門架設這個服務提供RD團隊整合使用,對於使用是絲毫不陌生,但是建置卻完全沒有經驗。沒想到現在已經轉眼間來到了6.1版本,介面跟架構看起來調整的更鮮艷與簡潔(?),我知道ELK目前在windows上面仍然是有一鍵安裝的版本。對於開發要測試的需求上已經相當足夠(連結),但因為我們目前對外主機主要都是CentOS,因此我這次預計實作如下:
假設我有2台CentOS主機的情境下(一台稱為A Host, 一台稱作B Host),如何透過各別安裝elasticsearch的docker 容器,來串連成elasticsearch 的集群。
同一台的多個容器理論上是相對簡單的,而這邊會遇到的問題,主要的關鍵就是如何解決跨主機間docker容器的通信問題,網路架構也通常都是應用程式間管控較為複雜的一個部分
這邊我打算採用Docker Swarm,Swarm為Docker自行開發的容器調度工具,其中的跨主機建立overlay網路功能看起來是非常符合我的情境需求,由於是Docker平台內建工具,看起來並不需要額外的安裝與學習,因此我先從這套工具開始著手,至於關於其他容器調度工具還包含了,Kubernetes、Mesos等。甚至現在的顯學看起來是Kubernetes(k8s),有許多的討論也直指要如何決定該採用哪種方案。
目前看到這一篇(連結)是相對從各面向都有討論到,有興趣的可以看看
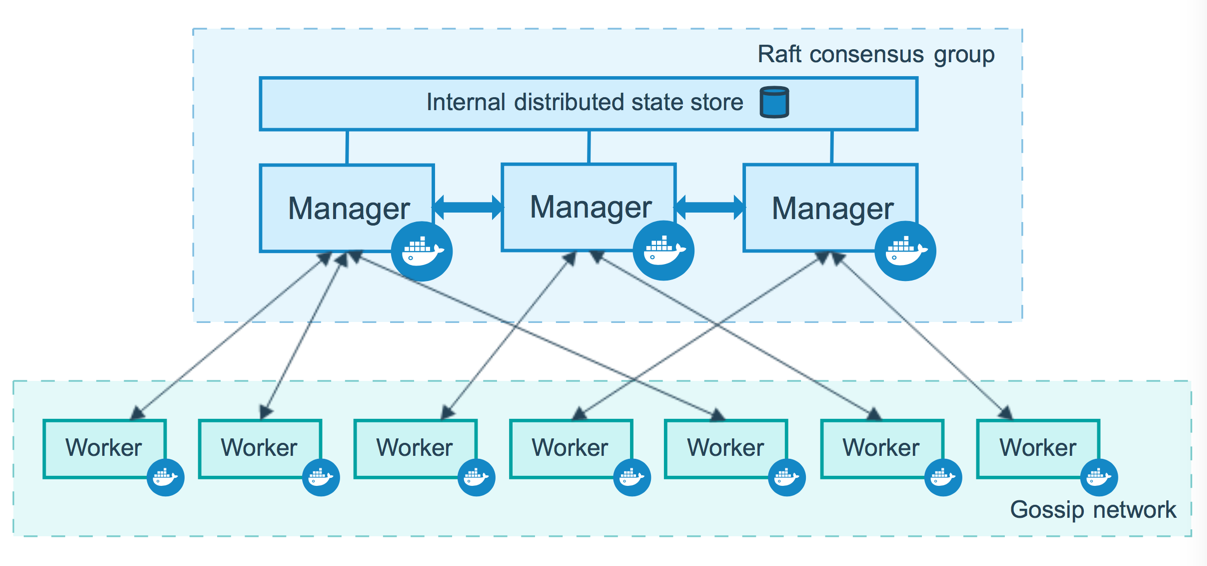
Docker swarm的架構圖(來自Docker官網)
從docker 1.9版開始,DockerSwarm已經是內建工具,因此透過以下指令,就可以將主機宣告成DockerSwarm的Manager主機(第一台總是master嘛)
sudo docker swarm init
若有成功啟動DockerSwarm的話,會提示以下訊息
docker swarm join –token SWMTKN-1-5wsc3yya3e87w2e84jkzbpieubpxr9v6qwnbj87m6t2ynv7kxm-8q5amih216368atw8adklx24f %A Host IP%:2377
這個hint很明顯就是我們可以在其他的Host(稱作Worker),透過以上指令來加入到Manager下的叢集中。同時他是透過A Host的2377 Port來進行串連
但假如希望建立起來的Swarm使用其他Port的話,我們可以使用以下指令來做
docker swarm init –advertise-addr=%A Host IP% –listen-addr %A Host IP%:2377
所以我們也可以使用這句語法檢查,是否有啟動了這兩個Port
sudo netstat -nap | grep ^tcp.*dockerd
正常應該會列出對應的2377與7946
tcp6 0 0 :::7946 :::* LISTEN 28184/dockerd
tcp6 0 0 :::2377 :::* LISTEN 28184/dockerd
接著我們在B Host上,輸入剛剛建立完swarm manager 所提示的加入語法
docker swarm join –token SWMTKN-1-5wsc3yya3e87w2e84jkzbpieubpxr9v6qwnbj87m6t2ynv7kxm-8q5amih216368atw8adklx24f %A Host IP%:2377
在這邊若有無法加入的情況的話,可以往防火牆先檢查,若是防火牆確定有通(telnet看看),那我這邊有遇到原本怎樣都加入不了,但是重開機、重啟docker後,就可以加入的情況。
若Worker成功加入Swarm的話,我們可以在A Host輸入以下指令確認是否節點都完整
docker node ls

既然A-B Host已經加入了同一個網路架構,接著就是建立覆疊網路
sudo docker network create –driver overlay –attachable es_net
註:這邊–attachable 若後續要透過run 語法加入指定網路的話,參數一定要加,是不是Docker Compose就不用加,我不確定
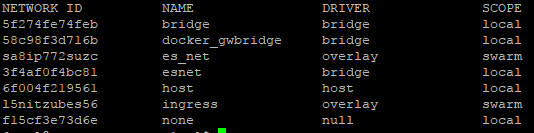
成功建立overlay網路後,我們就可以透過以下指令看到我們的網路已經被建立起來,SCOPE是顯示swarm , Driver是顯示overlay
sudo docker network ls
現在網路架構已經看似完成,接著我們來準備Elasticsearh的服務配置吧
這邊我寫了一個腳本來自動建立elasticsearch的相關目錄,目前只要elasticsearch會異動到的檔案目錄權限要開啟來,否則之後容器啟動後,會有權限例外產生:
腳本中改777的部分都是因為遇到所以加上去的,可以自行改成合適的權限配置。
sudo cd /mnt
sudo mkdir elasticsearch
cd elasticsearch
sudo git init
sudo git remote add origin "http://git server ip/scm/mes/elasticsearch.git"
sudo git pull origin master
sudo mkdir config/scripts
sudo mkdir esdatadir
cd esdatadir
sudo mkdir log
sudo mkdir data
sudo chmod 777 /mnt/elasticsearch/esdatadir/*
sudo chmod 777 /mnt/elasticsearch/config/scripts
cd /mnt/elasticsearch
config下的檔案,因為A, B Host各自擁有自己的獨立硬碟,因此我假設他們的環境配置應該都一致,jvm.options、log4j2.properties、檔案都一樣,只有Elasticsearch的yml檔會有些許差異:
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
cluster.name: meso_es_cluster1
node.master: true #if worker then mark it
node.name: ${HOSTNAME}
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["A HOST IP", "B HOST IP"]
以上都完成以後,就是來啟動Docker 容器的時候了,以A Host為例,啟動語法如下,B Host只是改–name成es2
sudo docker run -d -v /mnt/elasticsearch/esdatadir/data:/var/lib/elasticsearch -v /mnt/elasticsearch/esdatadir/log:/var/log/elasticsearch -v /mnt/elasticsearch/config:/usr/share/elasticsearch/config -p 9200:9200 -p 9300:9300 --net=es_net --name es1 --security-opt seccomp=unconfined -e "bootstrap.memory_lock=true" -e ES_JAVA_OPTS="-Xms1g -Xmx1g" --ulimit memlock=-1:-1 elasticsearch:5.6.6
分別執行後,我們可以看到docker ps 下是否狀態是正常在up的。
補充說明,啟動es容器時,我曾經發現會有以下的錯誤訊息:max virtual memory areas vm.max_map_count [65530] is too low(請透過docker logs查看)
這個問題若資源分配問題的話,可以透過以下指令解決:
sudo sysctl -w vm.max_map_count=262144
但我也有一個疑問,logs是記錄容器內部的jvm的錯誤,但是我是在容器外部下語法可解決,這個原因我確實不清楚就是了..
若都是正常,我們可以透過elasticsearch的Api來檢查我們的es cluster是否有正常運作起來
從瀏覽器輸入A Host IP:9200,會返回相關json資訊,若是如下,我們可以認定cluster有啟動,而且服務版本正確,
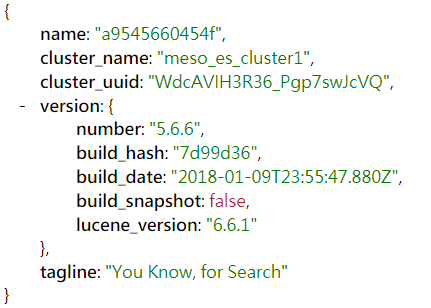
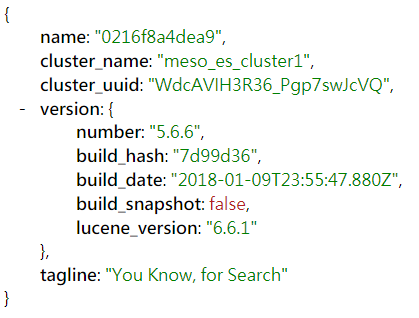
可以看到name的部分,就正是各別主機上Docker 容器的name,而cluster_name因為配置所以會一致、而若有正確加入的話,cluster_uuid必須要一致
註:我在實作的時候,就一直遇到B Host啟動的起來,但是他無法加入cluster,所以cluster_uuid一直顯示為_na_,後來竟然是整個docker服務重啟就好了,這個羅生門,讓我相信3R的救命招(Recycle, Reset, Reboot),測試期間,也可以透過docker exec -it B HOST Container IP ping -c 3 A_Host_IP來看看是否可以透過容器內解析出跨主機的另一個同網路下的容器名稱
如何觀察Elasticsearch的Cluster狀態呢?具瞭解在es 2.x版本的時候,有一套es的plugin,叫作kopf,是拿來可以直接透過es api來監控es服務的工具
後來5.x版以後,發現plugin功能被拔掉了,取而代之是獨立的”cerebro“套件可以達成完全一樣的功能,看來是同個作者寫的。
介面如下
只要在Node Address輸入A Host es容器名稱:9200(注意容器互連必須透過容器名稱,而不能只是ip),就可以看到以下的dashboard,相當的方便,除了可以即時監控Node的資源使用狀況,也可以看到目前的index數量與使用狀況、空間
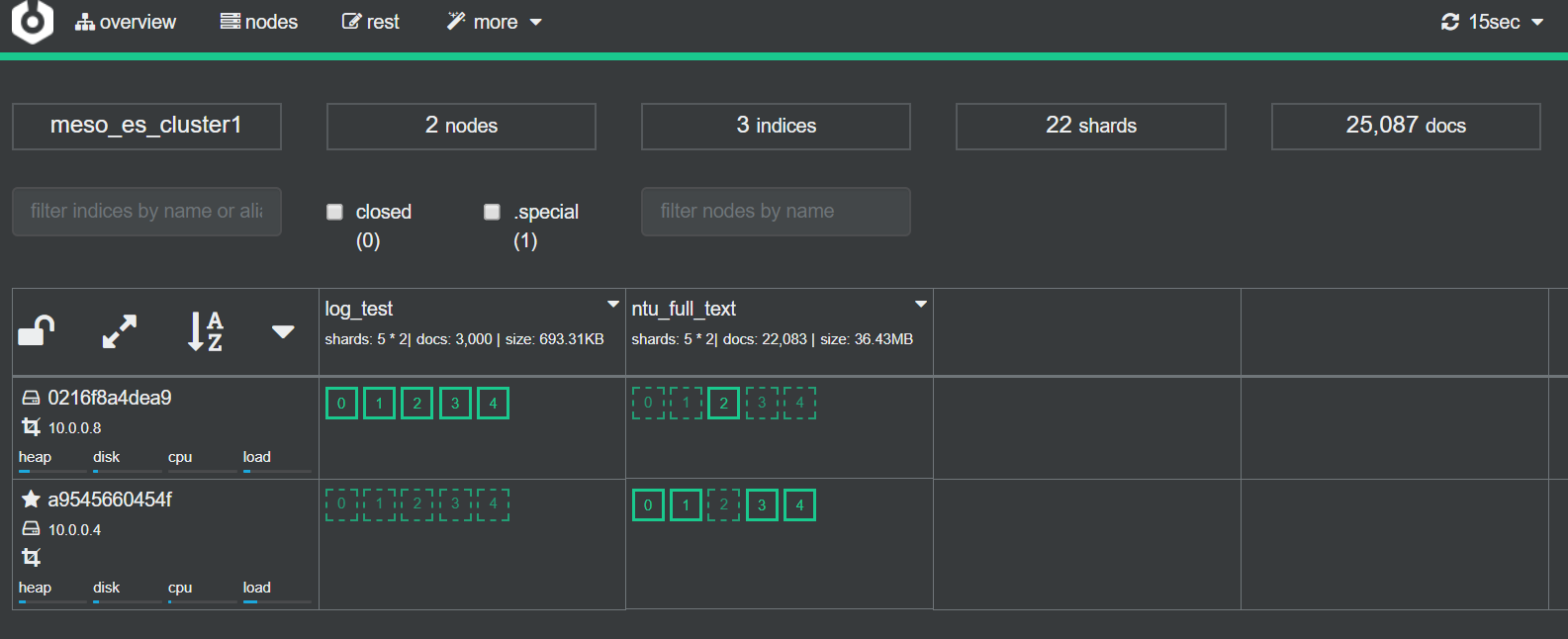
cerebro 這邊,只需要透過以下指令,就可以啟動:
sudo docker run -d -p 9000:9000 –name cerebro –net es_net yannart/cerebro:latest
同場加映Kibana 5.6.6的啟動指令
sudo docker run –name meso-kibana –link es1:elasticsearch –net es_net -p 5601:5601 -d kibana:5.6.6
透過A Host IP:5601啟用Kibana後,就可加入已經自定好的Index pattern來使用囉