一直以來都知道.netcore可以開始跨平台運作在linux上,因此運作在 docker的container中也是可行的
不過最近因為要研究apigateway,需要模擬infra的架構 ,因此需要在本機環境buildup起來多台主機的模式
沒想到入坑玩了一下,就發現,其實眉眉角角也不少,但來來回回操作後,其實是相對會愈來愈熟悉
首頁,我solution的構成包含了以下幾層 (apigateway還可做loadbalance,再加個nginx就可以, 不是這次的重點)
1.Redis(多台 instance作counter的cache)
這次主要研究的機制為 3跟4之間的協作機制
docker-compose
為了方便 重建,這次採用 docker-compose的yaml來維護(以下情境的container -name 都一般化了,只需要區分角色就好)
version: "3"
services:
nginx:
build: ./nginx
container_name: core-app.local
ports:
- "80:80"
- "443:443"
depends_on:
- core-app-gateway1
# network_mode: "host"
networks:
- backend
consul1:
image: consul
container_name: node1
command: agent -server -bootstrap-expect=2 -node=node1 -bind=0.0.0.0 -client=0.0.0.0 -datacenter=dc1
# network_mode: "host"
networks:
- backend
consul2:
image: consul
container_name: node2
command: agent -server -retry-join=node1 -node=node2 -bind=0.0.0.0 -client=0.0.0.0 -datacenter=dc1
depends_on:
- consul1
# network_mode: "host"
networks:
- backend
consul3:
image: consul
hostname: discover-center
container_name: node3
command: agent -retry-join=node1 -node=node3 -bind=0.0.0.0 -client=0.0.0.0 -datacenter=dc1 -ui
ports:
- 8500:8500
depends_on:
- consul1
- consul2
#network_mode: "host"
networks:
- backend
redis:
container_name: myredis
image: redis:6.0.6
restart: always
ports:
- 6379:6379
privileged: true
command: redis-server /etc/redis/redis.conf --appendonly yes
volumes:
- $PWD/data:/data
- $PWD/conf/redis.conf:/etc/redis/redis.conf
networks:
- backend
core-app-discover-a1:
build: ./dotnetapp/dotnetapp-discover
hostname: webapp1
environment:
- HOSTNAME=http://0.0.0.0:40001
- SERVER_HOSTNAME=http://192.168.1.115
- SERVER_PORT=8500
- CLIENT_HOSTNAME=http://core-app-discover-a1
- CLIENT_PORT=40001
- SERVICE_NAME=core-app-discover-a
- RedisConnection=redis:6379,password=12345678,allowAdmin=true
depends_on:
- redis
- consul3
ports:
- "40001"
networks:
- backend
core-app-discover-a2:
build: ./dotnetapp/dotnetapp-discover
hostname: webapp2
environment:
- HOSTNAME=http://0.0.0.0:40001
- SERVER_HOSTNAME=http://192.168.1.115
- SERVER_PORT=8500
- CLIENT_HOSTNAME=http://core-app-discover-a2
- CLIENT_PORT=40001
- SERVICE_NAME=core-app-discover-a
- RedisConnection=redis:6379,password=12345678,allowAdmin=true
depends_on:
- redis
- consul3
ports:
- "40001"
networks:
- backend
core-app-discover-a3:
build: ./dotnetapp/dotnetapp-discover
hostname: webapp3
environment:
- HOSTNAME=http://0.0.0.0:40001
- SERVER_HOSTNAME=http://192.168.1.115
- SERVER_PORT=8500
- CLIENT_HOSTNAME=http://core-app-discover-a3
- CLIENT_PORT=40001
- SERVICE_NAME=core-app-discover-a
- RedisConnection=redis:6379,password=12345678,allowAdmin=true
depends_on:
- redis
- consul3
ports:
- "40001"
networks:
- backend
core-app-discover-b:
build: ./dotnetapp/dotnetapp-discover
hostname: webapp-b
environment:
- HOSTNAME=http://0.0.0.0:50001
- SERVER_HOSTNAME=http://192.168.1.115
- SERVER_PORT=8500
- CLIENT_HOSTNAME=http://core-app-discover-b
- CLIENT_PORT=50001
- SERVICE_NAME=core-app-discover-b
- RedisConnection=192.168.1.115:6379,password=xxxxxxx
depends_on:
- redis
- consul3
ports:
- "50001:50001"
networks:
- backend
core-app-discover-c:
build: ./dotnetapp/dotnetapp-discover
hostname: webapp-c
environment:
- HOSTNAME=http://0.0.0.0:50002
- SERVER_HOSTNAME=http://192.168.1.115
- SERVER_PORT=8500
- CLIENT_HOSTNAME=http://core-app-discover-c
- CLIENT_PORT=50002
- SERVICE_NAME=core-app-discover-c
- RedisConnection=192.168.1.115:6379,password=xxxxxxx
depends_on:
- redis
- consul3
ports:
- "50002:50002"
networks:
- backend
core-app-gateway1:
build: ./dotnetapp/dotnetapp-gateway
hostname: gateway1
environment:
- HOSTNAME=http://0.0.0.0:20001
- SERVER_HOSTNAME=http://192.168.1.115
- SERVER_PORT=8500
- CLIENT_HOSTNAME=http://192.168.1.115
- CLIENT_PORT=20001
- SERVICE_NAME=core-app-gateway1
depends_on:
- consul3
ports:
- 20001:20001
networks:
- backend
networks:
backend:
driver: bridge
以上yaml就會建立一個network讓 container之前可以用 hostname來通訊。
這次研究的過程,會發現一件事情就是若要綁service discovery,那麼每個末端的webapp都需要跟register center做註冊,並提供一個health接口。但是若要做到auto scale,那依賴docker-compose所做的scale就會綁定動態的host_name(有序號),因此在此不建議 用scale直接長n台容器,而是先用多個端點來建置(如我的a1、a2、a3三台)
.netcore application的Dockerfile
以下是webapp的dockerfile (gateway的打包方式差不多,就不貼了)
FROM mcr.microsoft.com/dotnet/sdk:6.0-alpine AS base
WORKDIR /app
EXPOSE 80
EXPOSE 443
FROM mcr.microsoft.com/dotnet/sdk:6.0-alpine AS build
WORKDIR /src
COPY ["dotnetapp-discover.csproj", "dotnetapp-discover/"]
RUN dotnet restore "dotnetapp-discover/dotnetapp-discover.csproj"
COPY . ./dotnetapp-discover
WORKDIR "/src/dotnetapp-discover"
RUN dotnet build "dotnetapp-discover.csproj" -c Release -o /app/build
FROM build AS publish
RUN dotnet publish "dotnetapp-discover.csproj" -c Release -o /app/publish
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "dotnetapp-discover.dll"]
為了計數器功能與多台sharing cache,因此這次 還 模擬了一下連redis
public static IServiceCollection AddCacheService(this IServiceCollection services)
{
var redisConnection = Environment.GetEnvironmentVariable("RedisConnection");
#if DEBUG
redisConnection = "192.168.1.115:6379,password=xxxxxx,allowAdmin =true";
#endif
services.AddSingleton<IConnectionMultiplexer>(
ConnectionMultiplexer.Connect(redisConnection)
);
return services;
}註∶為了反覆測試,才加上allow admin,不然這個開關是很危險的,可以直接flush掉你的所有快取(清空)
Redis記錄的Log型態
註冊Service Discovery
ApiGateway跟WebApp我都有跟Consul註冊Service Discovery
static void RegisterConsul(string serviceName, string serverHostName , string serverPort, string clientHostName , string clientPort, IHostApplicationLifetime appLifeTime)
{
using var consulClient = new Consul.ConsulClient(p =>
{ p.Address = new Uri($"{serverHostName}:{serverPort}"); });
var registration = new AgentServiceRegistration()
{
Check = new AgentServiceCheck()
{
Interval = TimeSpan.FromSeconds(10),
HTTP = $"{clientHostName}{(clientPort == string.Empty ? "" : $":{clientPort}")}/health",
Timeout = TimeSpan.FromSeconds(5),
Method = "GET",
Name = "check",
},
ID = Guid.NewGuid().ToString(),
Name = serviceName,
Address = Dns.GetHostName(),
Port = int.Parse(clientPort),
};
try
{
consulClient.Agent.ServiceRegister(registration).Wait();
}
catch (Exception e)
{
Console.WriteLine(e);
}
//web服務停止時,向Consul解註冊
consulClient.Agent.ServiceDeregister(registration.ID).Wait();
}以上function可以在program.cs的startup時期先進行註冊,而這個function所有的參數一樣可以來自於 docker-compose
自動生成HealthCheck端點
在webapp的startup可以使用以下語法就長出health接口
builder.Services.AddHealthChecks();
app.MapHealthChecks("/health", new HealthCheckOptions()
{
ResultStatusCodes =
{
[Microsoft.Extensions.Diagnostics.HealthChecks.HealthStatus.Healthy] = StatusCodes.Status200OK,
[Microsoft.Extensions.Diagnostics.HealthChecks.HealthStatus.Degraded] = StatusCodes.Status200OK,
[Microsoft.Extensions.Diagnostics.HealthChecks.HealthStatus.Unhealthy] = StatusCodes.Status503ServiceUnavailable
}
});但還是要視服務加上MapHealthChecks的ResultStatus的設定,以consul來說,就是回200就好了,若沒有加上這個設定,其實health的回應並不是200,所以會被視為失敗
正常情況打 health的接口
Ocelot的設定檔
最後就是ocelot的json設定,傳統的Ocelot自已就有Load-Balance機制,因此若有多台Downstream的服務,本來就可以用以下設定去管理服務
不過這樣做的缺點就是若隨時要增減 容器/主機時,都要再去重新配置設定檔。造成主機可能的reset與維運上的難度,因此透過Service Discovery的好處就浮上了臺面!以下的配置,只需要注意,不用定義DownStream的Host,只要給一個ServiceName,這個ServiceName要跟WebApp在Startup的時候註冊的一樣。並在最後GloablConfiguration有註冊Service DiscoveryProvider的設定,就可以打通ApiGateway跟Service Discovery之間的便利機制。
{
"Routes": [
{
"DownstreamPathTemplate": "/test",
"DownstreamScheme": "http",
"UpstreamPathTemplate": "/newapi/get",
"UpstreamHttpMethod": [
"Get"
],
"ServiceName": "core-app-discover-a",
"LoadBalancerOptions": {
"Type": "LeastConnection"
}
},
{
"DownstreamPathTemplate": "/test/list",
"DownstreamScheme": "http",
"UpstreamPathTemplate": "/newapi/list",
"UpstreamHttpMethod": [
"Get"
],
"ServiceName": "core-app-discover-a",
"LoadBalancerOptions": {
"Type": "LeastConnection"
}
},
{
"DownstreamPathTemplate": "/test",
"DownstreamScheme": "http",
"DownstreamHttpMethod": "DELETE",
"UpstreamPathTemplate": "/newapi/reset",
"UpstreamHttpMethod": [
"Get"
],
"ServiceName": "core-app-discover-a"
},
{
"Key": "api1",
"DownstreamPathTemplate": "/test/list",
"DownstreamScheme": "http",
"UpstreamPathTemplate": "/newapi/list1",
"UpstreamHttpMethod": [
"Get"
],
"ServiceName": "core-app-discover-a"
},
{
"Key": "api2",
"DownstreamPathTemplate": "/test/list",
"DownstreamScheme": "http",
"UpstreamPathTemplate": "/newapi/list2",
"UpstreamHttpMethod": [
"Get"
],
"ServiceName": "core-app-discover-a"
}
],
"Aggregates": [
{
"RouteKeys": [
"api1",
"api2"
],
"UpstreamPathTemplate": "/newapi/listall"
}
],
"GlobalConfiguration ": {
"BaseUrl": "http://0.0.0.0:20001",
"ServiceDiscoveryProvider": {
"Scheme": "http",
"Host": "192.168.1.115",
"Port": 8500,
"Type": "PollConsul",
"PollingInterval": 100
},
"QoSOptions": {
"ExceptionsAllowedBeforeBreaking": 0,
"DurationOfBreak": 0,
"TimeoutValue": 0
},
"LoadBalancerOptions": {
"Type": "LeastConnection",
"Key": null,
"Expiry": 0
},
"DownstreamScheme": "http",
"HttpHandlerOptions": {
"AllowAutoRedirect": false,
"UseCookieContainer": false,
"UseTracing": false
}
}
}
上述的ApiGateway一樣用DockerFile把專案包成Image
整合測試
docker-compose up -d –force-recreate
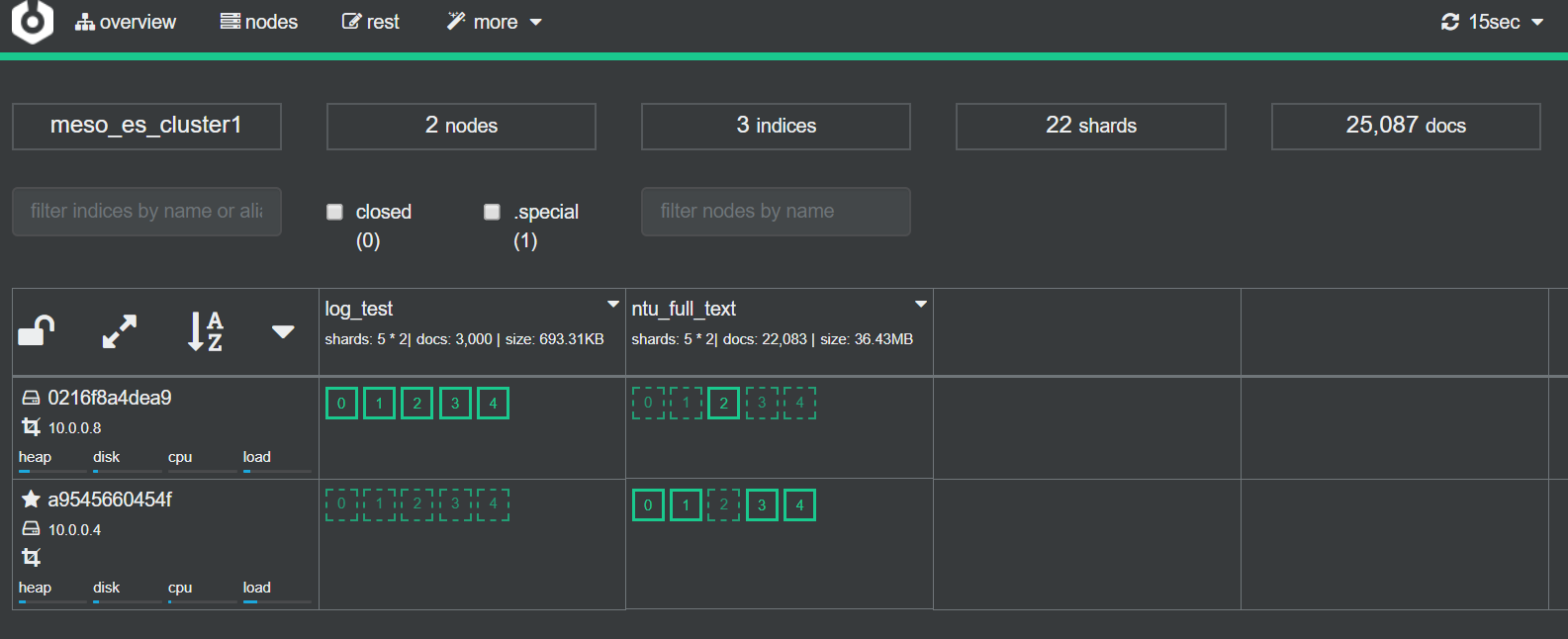
會看到一次起來這麼多服務
http://localhost:20001/newapi/get(透過api gateway打到downstream的service)
這邊多請求幾次會發現machineName一直在webapp1~3跳來跑去,採用load-balance的機制,ocelot會採用你設定的策略進行請求分派
ApiGateway有Aggregation的功能,就是可以把多個Api請求Combine在一起,讓請求變成1次,減少頻寬的消耗,這邊我也做了配置,來試看看吧
出於Ocelot.json的設定檔段落:
透過api gateway的組合讓 多個 Api可以一次 回傳
最後,打了很多次請求後,來總覽一下所有的請求摘要(程式是自已另外撈Redis的Request記錄來統計)
http://localhost:20001/newapi/list(透過api gateway打到down stream的service)
嘗試Docker Stop某一台 Discover-a1的服務,Consul DashBoard馬上就看的到紅點了!
這個時候再去打 之前load-balance的端點http://localhost:20001/newapi/get,會發現machineName會避開stop掉的服務只剩下 webapp1跟webapp3在輪循,因此做到了後端服務品質的保護
小插曲
ID不小心用成了Guid.New,所以會導致重新啟動就又拿到新的ID,造成了多一個Instance。但舊的也活了,因為他們的HealthCheck是一樣的
其實ApiGateway的議題,從Infra的角度上,可以玩的東西還有很多。
像是他也支援RateLimiting, QualityOfService(Polly) , 服務聚合(Aggregation)等機制,都可以從他們的官方文件看到設定方式,算是配置上不算太複雜。
不過 Ocelot在.net這邊發展一陣子後,近一年好像停更了!取而代之的好像是其他語言寫的更強的Apigateway: Envoy。
Envoy資源https://www.envoyproxy.io/docs/envoy/latest/intro/what_is_envoy https://www.netfos.com.tw/Projects/netfos/pages/solution/plan/20210111_plan.html
若只是要輕量級的,或是想參考其架構設計的,倒是可以翻github出來看看~
Github∶ https://github.com/ThreeMammals/Ocelot
這次Lab程式碼
若要拿去玩的,請把Ip, Password自行調整一下
一些文章的參考
https://ocelot.readthedocs.io/en/latest/features/servicediscovery.html?highlight=ServiceDiscoveryProvider
https://ocelot.readthedocs.io/en/latest/features/servicediscovery.html?highlight=ServiceDiscoveryProvider#
https://www.uj5u.com/net/232249.html